JVM内存分配机制介绍
本文针对的是hotspot虚拟机, jdk版本1.8的虚拟机进行介绍。
程序计数器
线程私有,可以看做是当前线程所执行的字节码的行号,用于下一次线程切换的时候虚拟机定位到上一次执行的位置。
虚拟机栈
在一个时间点,只会有一个活动的栈帧,通常叫作当前帧,方法所在的类叫作当前类。
如果在该方法中调用了其他方法,对应的新的栈帧会被创建出来,成为新的当前帧,一直到它返回结果或者执行结束。JVM直接对Java栈的操作只有两个,就是对栈帧的压栈和出栈。
总结几点如下:
- 线程私有,生命周期与线程相同。描述的是方法执行的内存模型。
- 进入方法时对应入栈,方法结束的时候对应出栈。
- 该区域存储着局部变量,操作数,方法出口等信息。
方法区
线程共享。用于存储类信息、常量池、静态变量、JIT编译后的代码等数据。具体放在哪里,不同的实现可以放在不同的地方。
一般情况可以理解成class文件在内存中的存放位置。
在1.7和1.8之后的实现逻辑有所不同。
由于该区域大小一般较小,所以不会对该区域进行垃圾回收。所以在1.7之前的版本,有可能会因为字符串常量池过大导致该区域内存溢出(Permgen space out of memory error)。
永久代(PermGen)和方法区之间是什么关系?
方法区是虚拟机规范中的一部分,而永久代是hotspot虚拟机用来实现方法区的, 是hotspot虚拟机特有的。
在1.7之前,永久代就是方法区。
从1.8开始,hotspot移除了永久代,将方法区的实现分为两部分:
- 将原先永久代中的类的静态变量和常量池放入堆中
- 将类的元信息放入元空间(metaspace )中
上文中介绍到的几个概念分别做一一说明:
- 类型信息:包括类的完整名称,父类名称等,该类型信息是在类加载器加载类的时候从类文件中提取出来的。
- 元空间:metaspace ,是与堆不相连的一块本地内存。Java将其放在本地内存中, 默认只受本地内存大小的限制,也就是说本地内存剩余多少,理论上Metaspace就可以有多大。可以使用参数
-XX:MaxMetaspaceSize参数来指定 metaspace 区域的大小 - 字面量:给基本类型变量赋值的方式就叫做字面量或者字面值
- 常量池:java中的常量池分为两种, 静态常量池和运行时常量池(此处指的是运行时常量池):
- 静态常量池。即class文件中的常量池,主要用于存放两大类常量:字面量(Literal)和符号引用量(Symbolic References)。 其中字面量相当于Java语言层面常量的概念,如文本字符串,声明为final的常量值等,而符号引用则属于编译原理方面的概念,包括了如下三种类型的常量:
- 类和接口的全限定名
- 字段名称和描述符
- 方法名称和描述符
- 运行时常量池。jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中
- 静态常量池。即class文件中的常量池,主要用于存放两大类常量:字面量(Literal)和符号引用量(Symbolic References)。 其中字面量相当于Java语言层面常量的概念,如文本字符串,声明为final的常量值等,而符号引用则属于编译原理方面的概念,包括了如下三种类型的常量:
直接内存(堆外内存)
不是虚拟机运行时数据区的一部分。JDK中主要是NIO库中一些直接操作本地内存的类, 例如DirectByteBuffer。
其内存大小虽然不受堆最大内存的制约,但是也会受到操作系统最大内存的制约。
Java中NIO的核心缓冲ByteBuffer,所有的IO操作都是通过这个ByteBuffer进行的。Bytebuffer有两种: HeapByteBuffer和DirectByteBuffer,下面是这两种内存的分配方式:
1 | //分配HeapByteBuffer |
两者之间的区别:
| DirectByteBuffer | HeapByteBuffer | |
|---|---|---|
| 涉及到IO时拷贝情况 | 不需要拷贝,直接使用 | 需要拷贝到HeapByteBuffer后再使用 |
| 创建开销 | 需要调用原生方法从系统申请内存, 所以创建开销较大。 不过一般应用会提前申请一大块内存, 然后自己实现内存管理机制, 例如netty | 从JVM堆上分配,速度很快,所以创建开销小 |
| 对于GC的影响 | 不存在于堆栈中, 但是有冰山现象的问题 | 频繁申请新的对象会引发GC |
为啥要使用堆外内存?
- 可以在进程间共享,减少虚拟机间的复制
- 对垃圾回收停顿的改善:如果应用中包含大量长期存活的对象,发生YGC或者FullGC的频率就会比较高,此时如果将这些内存放到堆外,就会减少堆中发生GC的次数,提高垃圾回收效率
- 在某些场景下可以提升程序I/O操纵的性能。因为少去了将数据从堆内内存拷贝到堆外内存的步骤。
堆
JVM中空间占比最大的一块区域。被所有线程共享。几乎所有的对象实例和数组都会存储在此地。垃圾收集主要是针对此处进行工作。
主要分为新生代和老年代,见下图分配示意。
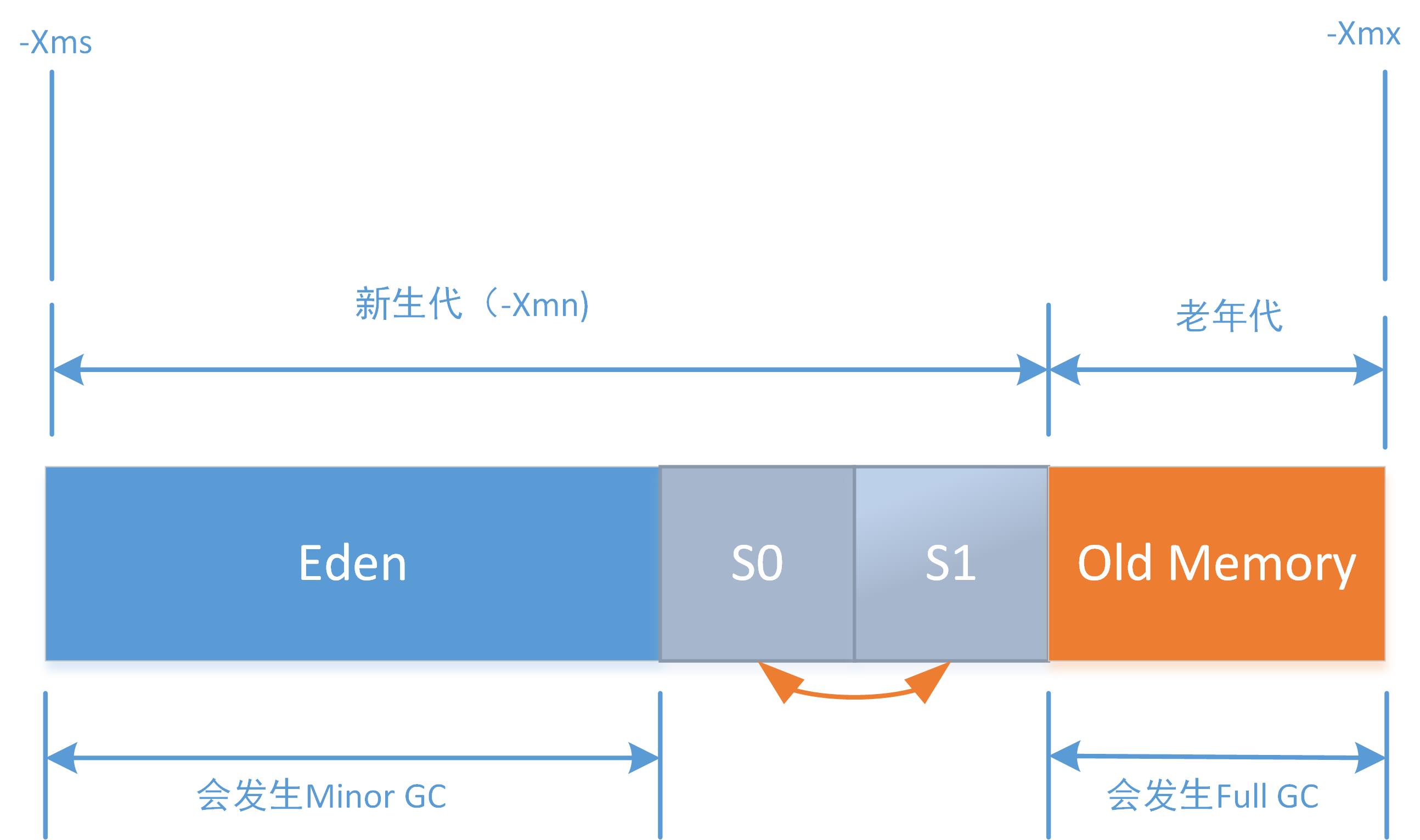
先讲述一下新生代的事。以下垃圾回收的算法其实也就是复制算法的实现。
新生代,顾名思义,Java中绝大部分对象都是在该区域被创建,存放新建创建的对象。其特点是对象更新速度快,因为Java中大多数对象都不需要存活很长时间(典型的就是局部变量)。该区域是进行垃圾回收频繁的区域,且进行的垃圾回收类型是Minor GC(GC发生的区域不是整个新生代,而是新生代中的Eden区)。
新生代又被分为Eden区,S0区,S1区(S代表Survivor)。默认参数是Eden区占新生代的绝大部分空间(8:1)。当一个对象被创建的时候,首先会在Eden区分配空间(对于大数组, 也有可能第一次就直接在老年代分配)。当Eden区没有足够的空间时,会触发一次Minor GC,此时会将存活的对象移动到S0,再将Eden清空。若再次发生Minor GC,则将Eden,S0中存活的对象移动到S1,再将Eden,S0清空。
这样对象就会反复在新生代的三个区之间来回移动,随着对象的移动,其GC年龄也会不断增加,当GC年龄达到一个默认值(15)的时候,就会将该对象实例移动到老年代,如此,老年代的数据就出来了。所以,老年代的数据都是新生代中那些存活年龄很大的对象。
经过以上步骤,老年代已经呼之欲出了。当老年代空间不足时,也会触发一次GC,此时的GC又叫Full GC,比新生代发生的Minor GC要慢得多。
比如常见的在方法中new一个对象的写法, 如下所示:
Object obj = new Object();
在等于号右边 new Object()出来的对象是存储在堆上;
在等于号左边obj这个对象引用是存储在该方法的虚拟机栈上;
表示Object这个对象的class属性是存储在方法区上(运行时常量池);
jvm问题排查工具
1. 排查是否频繁full gc
当整个服务出现响应缓慢的时候, 一个可能的原因是此时jvm正在频繁的进行full gc, 那么如何确定是不是这个原因呢?可以使用jstat命令来判断(如果使用的是openjdk的docker, 一般路径在/usr/lib/jvm下), 步骤如下:
jps -l获取java进程的进程号- 查询GC状态
jstat -gc 6 1000, 其中 6表示JVM的进程号, 1000表示每隔1000ms打印
一次, 输出结果如下:

其中倒数第三列FGC表示full gc的次数, 如果一直在增长, 则很有可能是发生了OOM, 导致一直在full gc
若出现了full gc, 需要导出堆栈,命令如下:(有时候JVM已经处于假死状态,可能不会响应该命令)
1
26是进程号
jmap -dump:format=b,file=/var/logs/heap.hprof 6
2. JVM参数设置
启动参数加上如下:
1 | # oom的时候自动生成dump文件 |
注意, 有时候即使设置了此参数,也有可能无法生成对应的dump文件, 可能的原因有如下几个:
- JVM本身内存已经所剩无几:JVM 可能没有足够的内存来生成堆转储文件,特别是在堆栈溢出或其他严重内存问题发生时。
- 磁盘不够或目录权限错误:这个一般修改参数或增大磁盘即可
- OOM是发生在GC线程中:不过这个一般不太会可能发生
3. 分析工具使用
除了一些常用的命令之外, 一些图形化的工具也非常有助于分析问题
- 分析gc的log日志用
gcviewer, 下载之后直接使用java -jar命令启动即可 - 分析堆栈文件用MAT(Eclipse Memory Analyzer)、visualvm或者jprofile
参考资料: