一致性哈希算法解读
首先理解一下哈希函数的意思。
哈希函数
将任意长度的数据映射到有限长度的域上。
本质是对一段数据m进行杂糅,然后输出另一段固定长度的数据h,并将这个h作为这段数据的特征值。
基本原理就是将数据块m分成多段,每一段长度固定(如128位),若某段长度不足,则进行补位(如0或者1),然后对每一块都进行hash运算,再将这些数据进行迭代(比如相邻两段进行异或),最终得到一个数据。
普通哈希取模
先来看一下普通哈希取模是什么样的?
1 | c = hash(key) % n |
其中n为节点数目,计算得到的c为对应的节点编号。
假设现在总共有A,B,C三台服务器节点, 现在对某个key值哈希之后得到的值为5, 则c = 5 % 4 = 1, 表示该值存储在B节点上。
现在若需要增加一台服务器节点D,则此时c=5 % 5 = 0,表明该值存储在A服务器上,前后就会出现不一致。
这样当出现服务器新增、删除、宕机的时候,这样就会请求后端数据库,造成缓存穿透。因此普通的哈希取模定位key所在的服务器的方法会有问题。
综上, 普通哈希最大的缺点就是在扩容或缩容的时候, 会造成key定位的失效。
一致性哈希
一致性哈希算法不是对服务器数目取模,而是对2^32进行取模。
将2^32个数组织成一个圆环,从0到2^32-1, 整个空间按照顺时针方向组织,圆环的正上方的数是0, 0 点右侧的第一个数是1, 左侧的第一个数是2^32-1, 这样就组成一个hash环。
现在假设有四台服务器1,2,3,4,利用哈希算法计算出这四台服务器的哈希值(具体可以是服务器的IP等),其在圆环上的分布如图所示,同时假设有三个key,其代号分别是A、B、 C,计算其哈希之后得到的值在圆环的分布如图所示。
根据哈希环的规定,确定一个值在哪个服务器上存储,只需要从该key在哈希环的位置开始,按照顺时针方向找到的第一个服务器节点,就是该key存储的服务器。如下图所示,A存储在节点1上,B存储在节点2上,C存储在节点3上。
综上, 一致性哈希需要计算2次哈希值:
- 计算存储节点的哈希值,确定存储节点在环上的位置
- 计算key的哈希值, 确定key在环上的位置
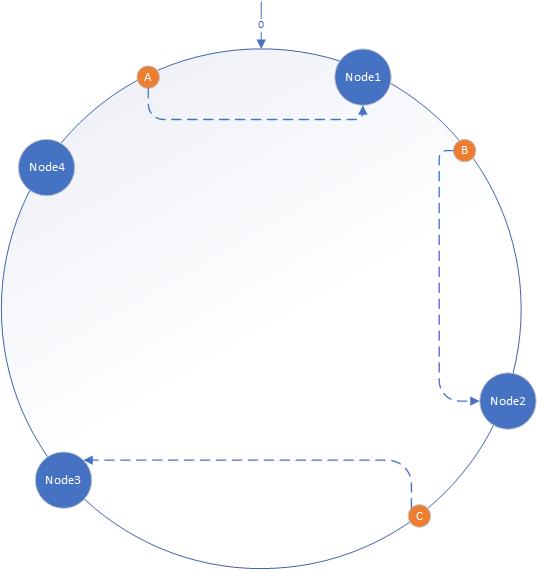
可以看到当节点3宕机的时候,对A、B无影响,只有C定位到节点4上,也就是说,当某个节点出现故障或者新增节点时,受影响的数据仅仅是此节点到其环空间中上一个节点的数据,其他的不会受到影响。故数据影响范围较小。
虚拟节点
这里有一个问题需要注意,当节点数量较少时,可能会导致环上节点分布不均匀,导致大部分数据会落在某一个或者某几个节点上。
为了保证数据能够均匀分布,一致性哈希算法引入了虚拟节点的概念,即对某一个实体节点计算多个哈希,每个计算结果都占据环上一个位置。
具体做法可以在服务器IP上增加编号来实现。在实际环境中,通常将每个实体节点设置32个虚拟节点甚至更大,保证数据均匀分布。