HashMap源码分析
基本原理
HashMap是由数组Node<K,V>[] table 和链表(或者树)组成的一个复合结构。
数组被分成一个个的桶(buket),通过下面的这个算法决定元素在桶中的位置:
1 | // n为数组长度,hash为key的哈希值 |
若p相同,则以链表形式存储。当链表长度超过阈值(TREEIFY_THRESHOLD=8)时,则将链表
转换为红黑树。
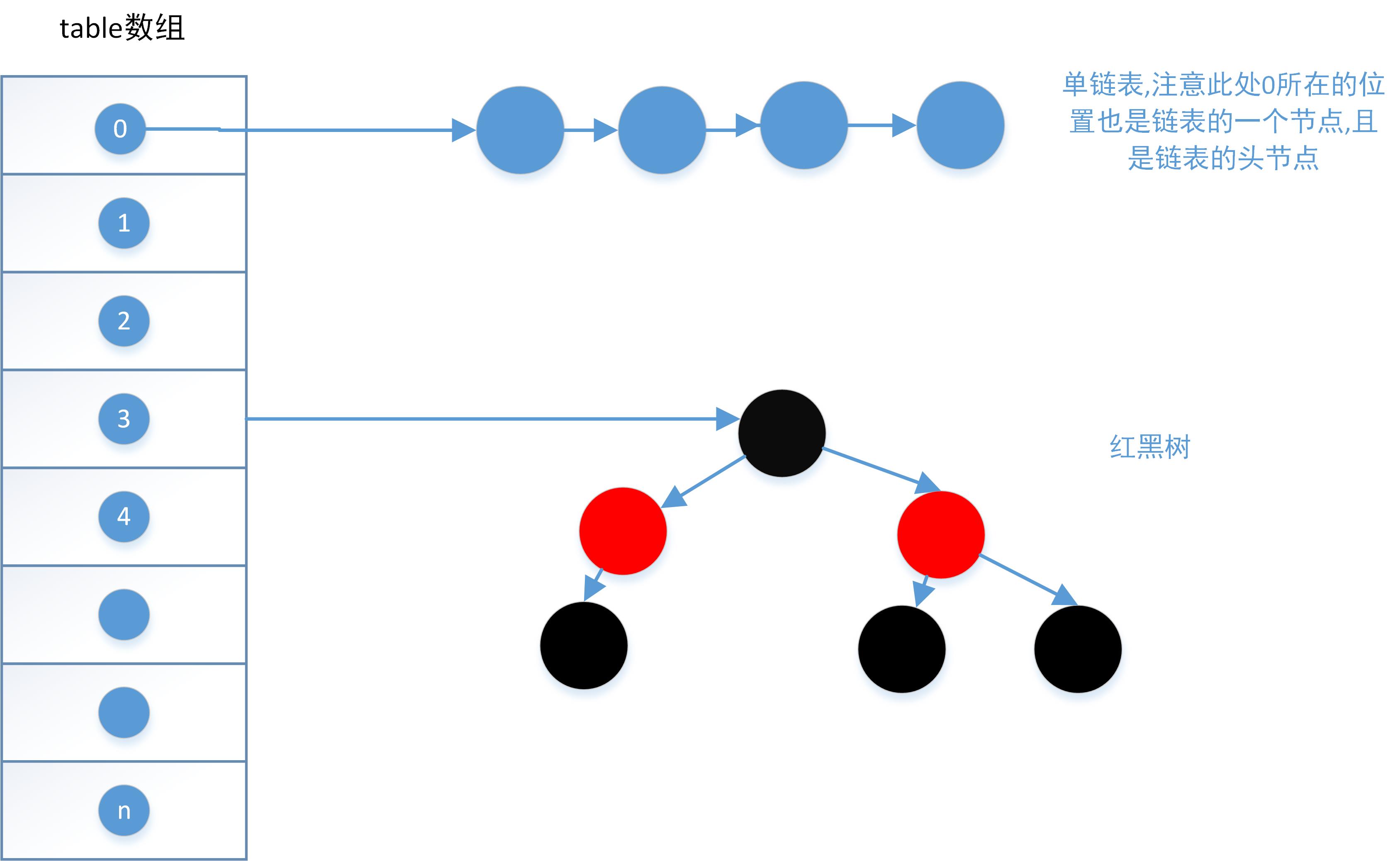
此处为什么需要这么做?
主要是基于查询的效率考虑。链表查询元素的时间复杂度为O(n),随着链表长度的增大,查询时间也会递增。而红黑树的时间复杂度为O(logn),此处是一个以空间换时间的典型案例。
HashMap中几个特殊值说明:
- initialCapacity:HashMap初始容量,默认为16
- loadFactor:负载因子,默认0.75
- threshold:键值对数量的最大值(不是table数组的长度),超过这个值,则需要扩容,会变为原先值的两倍
- TREEIFY_THRESHOLD:链表转换红黑树阈值,默认为8, 当超过该值时, 链表就会转换为红黑树
哈希值计算
key本身的哈希值不是通过hashCode得到的, 而是HashMap自己实现的一个算法。
1 | static final int hash(Object kye) { |
上述代码实现了将高位数据移位到低位进行异或运算,是因为有些数据计算出来的哈希值差异主要就在高位,而其哈希寻址是忽略容量以上的高位的,所以通过这样处理, 就能有效避免上述情况的哈希碰撞。现实中,构造哈希冲突并不是很难,恶意代码就有可能会通过该手段造成大量的哈希碰撞,造成服务器CPU大量占用。
插入流程
首先计算key的哈希值, 然后调用putVal()函数。
下图是putval()函数的源码, 就其中的关键几步进行说明

当数组为空,则调用
resize()函数进行数组的初始化操作。该处代码表明HashMap中数组的初始化并不是在new的时候,而是在第一次put的时候。使用
(n - 1) & hash计算数组下标,若当前项不存在,则调用newNode()函数在数组下标处新建一个节点。当以上条件都不满足, 说明该处索引已经存在节点,此时就该进行链表或树操作了。3、4、5是对应不同类型的。其中3是直接判断当前节点, 4则是树节点, 5是链表。 此处需要判断该节点处的key和待存入数据的key是否相等。判断相等的条件如下(之间是且的关系):
- 将要存入数据key的哈希值和数组下标处节点的哈希值相等
- 将要存入数据的key和数组下标处节点的key相等(此处相等是内存地址相等或者equals比较相等都可以)
该代码表明该处数组下标处的节点是树节点, 所以此时调用
putTreeVal()函数插入树节点。当3和4都不满足时,则表明该处是一个链表,则进行链表的遍历。
若一直能遍历到链表尾部,则在链表尾部新建一个节点储存当前待存入数据。然后判断是否要将链表(TREEIFY_THRESHOLD)转化为红黑树, 若是则调用
treeifyBin()函数进行链表的树化。若链表中某个节点的key与待存入数据的key相等(与第3步的判断条件一样),则退出遍历。
判断之前是否已经存在key值相同的节点,若是此时根据onlyIfAbsent参数来决定是否将之前节点的值更新为本次要插入的值(实际上map默认的put操作该值为true,表明是覆盖插入)
判断是否要进行扩容操作, 若是则调用
resize()函数进行扩容。注意此处的++resize操作可能导致线程不安全。
扩容
resize()函数。该函数有两个用途:
- 创建初始的存储数组
- 容量不足的时候, 进行扩容
下面是resize函数关键几步分析:

基本流程:
- 当扩容之前的数组长度大于最大值时,直接返回未扩容之前数组(也就是不进行扩容),此处表明当HashMap容量达到最大值时(Integer.MAX_VALUE),继续插入新值虽然不会报错, 但实际上并没有生效, 返回的仍是原数组。
- 当元素个数大于阈值(默认初始容量16 * 负载因子0.75 = 12)时进行扩容,将新数组长度和阈值都扩大为原先2倍
- 能进入该分支表明是第一次初始化,设置数组容量大小(指定值或者默认值)和阈值大小
- 重新初始化一个新的数组,数组长度是原先的2倍
- 开始进行重哈希,将原数组项的数据重新放入新的数组项里面,这是扩容时消耗时间最长的地方。此处需要遍历原数组, 具体步骤如下:
- 6处表明当前下标处没有值,则直接将元素插入到新数组项中
- 7处表明当前数组项是一个红黑树,进行红黑树的重新赋值
- 8处,当以上两种情况都不符合,肯定是链表节点,则进行链表的重哈希,需要遍历链表
链表节点的重哈希 有必要说明一下,此处设计的比较巧妙,具体描述可见文章:https://yikun.github.io/2015/04/01/Java-HashMap%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E7%8E%B0/
JDK中解释resize函数的说明大意如下:
当进行扩容时,因为我们每次扩容容量都是之前的2倍,任意元素在新数组中要么是原先的位置,要么是原位置移动2次幂的位置。
其具体原理是利用0与0或者1进行&运算结果都是0,这样在进行重hash的时候,不需要重新计算Hash值,只需要判断原先的Hash值新增的那一位是0还是1,若为0,则原先位置,若为1,则索引变为“oldCap+原索引”。
这地方有几点需要注意:
- 判断索引是否改变用的是 hash & oldCap,此处与计算索引值**(n - 1) & hash**需要区分开来
链表转化红黑树
treeifyBin()函数。在链表长度超过8的时候,使用该函数将链表转化为红黑树。
其主要思路如下:
- 当整个数组桶的长度小于64时,此时并不会进行树化操作,只是进行扩容。注意,在进行扩容的时候,链表的长度有可能会变短
- 将链表中的节点转化为树节点TreeNode,形成一个新的链表
- 将新链表节点赋值给给定的数组项
- 调用TreeNode的treefify()方法将该处的链表转化为红黑树,该函数大致步骤如下:
- 插入树节点元素,具体可以参考二叉搜索树的插入操作。在进行插入的时候,比较key的hash值来决定插入的方向。
- 插入完成之后开始调整红黑树,使其符合红黑树的特性
查找
getNode()函数。提供常数时间复杂度的查找效率。
根据
(n - 1) & hash计算得到该key所在的桶bucket,若桶不存在或者数组table为空,则直接返回null,根据这一点我们可以知道HashMap取元素的方法get和判断元素是否存在的contanins方法的时间复杂度都是O(1)当桶存在时,首先判断该桶上第一个节点是否就是要找的节点,若是直接返回该节点值
若不是,判断节点类型,若是红黑树,则遍历红黑树查找,若是链表,则遍历链表查找